Message Aggregation
Message aggregation, processing, and message persistence are common needs for PubNub customers. You can approach this in several ways, but the core concepts are the same. As your app grows, your channel count often grows with it. Aggregating data across many channels becomes an important concern.
Baseline approach and scaling limits
A common first approach is to aggregate on back‑end servers and subscribe the server to every channel. It’s natural to design around user interactions and handle aggregation later.

This diagram shows a publisher and a subscriber on a channel. The server subscribes to the same channel to receive messages. The issue appears at scale, as shown next.
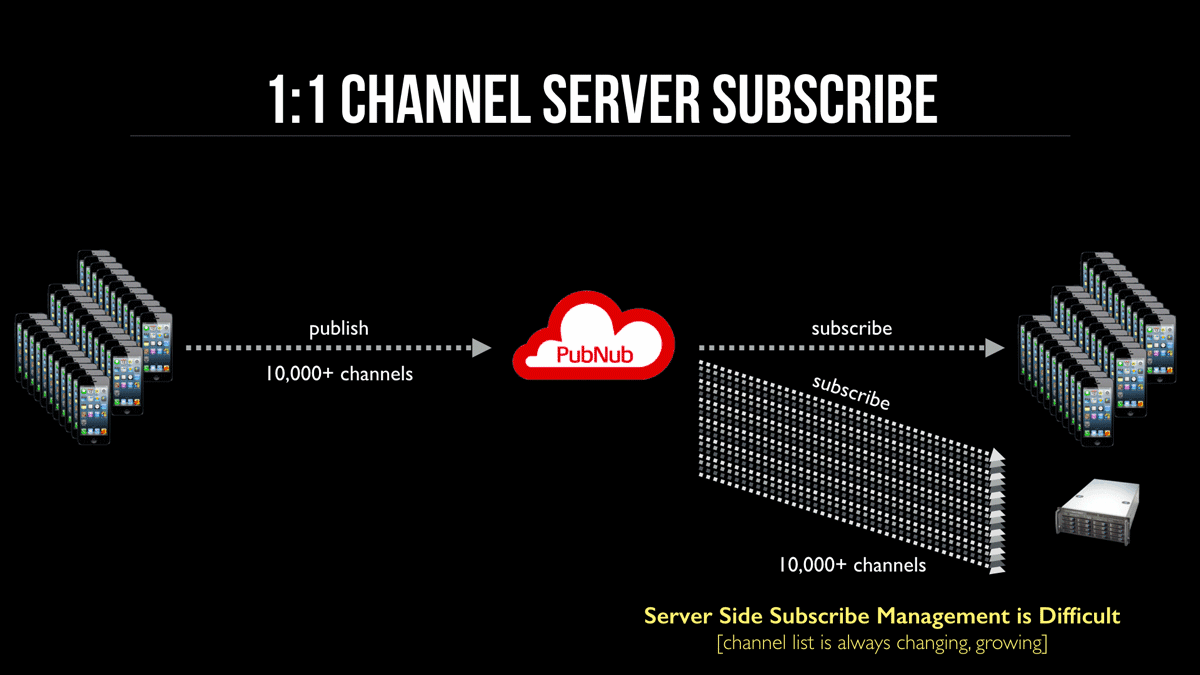
Scaling considerations
Adding a server subscriber to every channel creates management and throughput challenges:
- Channel list grows indefinitely
- Every new channel must add a server subscription without race conditions
- Server load is hard to predict and scale
- Message distribution is uneven
- Horizontal scaling becomes complex
High throughput and scalable
A better approach uses a finite set of channels dedicated to inbound messages. Dedicated ingress channels improve throughput, simplify horizontal scaling, and reduce hotspots and uneven distribution.

Server side
This setup uses eight dedicated Server Inbound channels, one per CPU core, with a consistent naming scheme such as server-inbound-1, server-inbound-2, and so on. Each subscriber process subscribes to one channel, and there are eight processes. The OS aligns processes to cores, which optimizes I/O. Having more processes than cores can slow I/O due to contention.
Client apps
Client apps dual‑publish to the normal channel and one server‑inbound shard. Use a consistent hash to shard publishes evenly across shards and clients.
Why sharding
With multiple processes, you want predictable load on each process. If messages concentrate on one process, it becomes a bottleneck. Poor sharding in distributed systems has caused single shards to receive most traffic and exceed capacity limits.
A typical scheme (used in Memcache/Membase/Couchbase) uses a CRC32 hash on a unique value, then a modulo operation with the shard count to distribute load evenly. You can also use an FNV-1a hash.
